
I Asked Four AIs to Research Data. Not One Asked Why.

The thinking is yours. The legwork is theirs.
Research is an important part of a student's life. It is also an important part of work life later on. Research also happens to be one of the key task areas that AI evangelists and marketeers highlight as a strength of Generative AI tools. But are Generative AI tools good at research? To answer that, first we need to be clear about what constitutes 'research', what are the phases of research, what skills are required to conduct research and what parts of research can be conducted well by Generative AI.
Research is the process of asking questions, gathering information, and constructing answers based on that information. The following diagram depicts the general process for research. There are several variations of the process — broadly, the stages involved are more or less as defined.
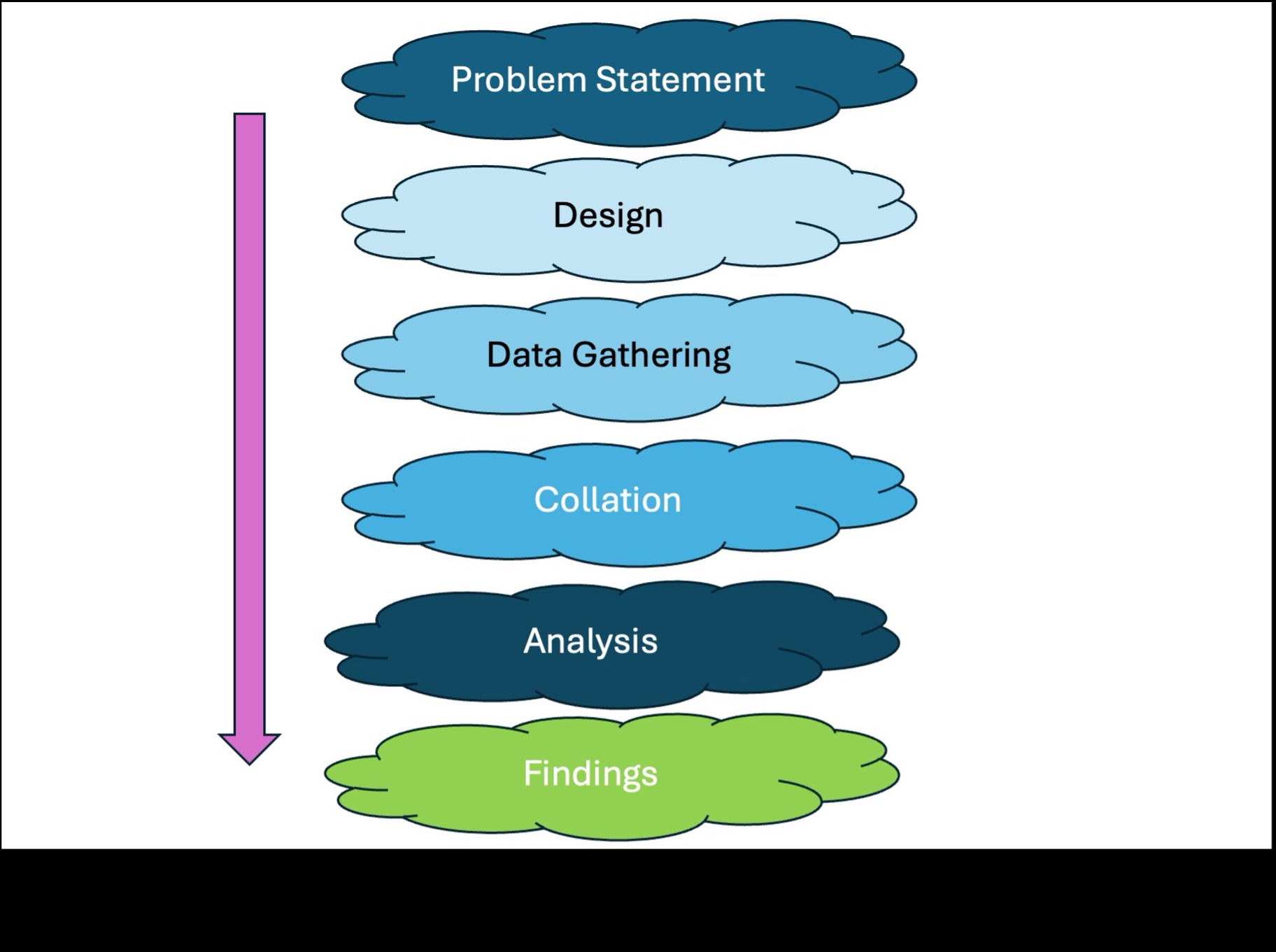
With each phase of research there are several sub-processes and tasks, depending on the complexity of the research scope, but for this article we will focus only on the high-level stages within the process.
Task Breakdown by Research Stages
Best Practice Tip: Let AI handle groundwork tasks while you shape and drive the critical experience of the research.

Case Study: AI Education Official Sources Analysis
Problem Statement
If you are conducting the research, you have to define the problem statement. Can you use Generative AI to define the statement? Of course, and many people are doing exactly that. Should you use Generative AI to define the problem statement? No. But that is my opinion and my reasons are as follows: The problem statement represents how you think, how you look at the world, how you perceive the problem and how you intend to solve the problem. If you outsource or delegate the thinking process once, you will do it again, and eventually you will not be able to perform that task easily or well — which amounts to a loss of skill. There is another reason: if you haven't done the initial thinking, you won't be able to evaluate if the subsequent processes or outputs are of appropriate quality or not.

Let's take a specific example. Last week, I decided to conduct research to find out the total number of 'Introduction to AI' courses available in the world as of July 15 2025. I gave the task to four different Generative AI platforms. ChatGPT, Gemini, and Grok gave me an immediate output based on assumptions and with disclaimers that determining an accurate number is challenging. The numbers they provided were of no use since the platforms had no idea what was the problem statement behind the research question. The fourth platform, Claude, took a different approach — it asked several clarifying questions about scope and methodology, and after each response, stated how and what it would look for. Better process. But still not the right question.
Not one of the four platforms asked why I wanted the data. All of them, including Claude, assumed I wanted the numbers for one of the following reasons: market survey, business intelligence, academic status evaluation, investment purposes.
Why do you think I wanted to conduct the research? What is the problem I am trying to solve or the gap I am trying to fill? Incidentally, I decided to do this research because of several conversations I had with students and young working professionals that week. The situation that emerged was that they all wanted to start some serious formal self-study on Generative AI because they felt they needed to inform themselves, but they could not decide why they would take any course: they had no way to evaluate if any of the courses had any value. They did not want to take even the free courses because they did not want to waste time listening to similar information. This is what is called consumer fatigue — the market is flooded with AI courses and AI marketing content and they all say more or less the same thing.
The problem statement for my research thus was: AI education is spreading as fast as AI itself. Under such circumstances, people are unable to verify the efficacy (value, quality, usefulness) of these courses, and thus unable to make a buying decision. This is applicable to pretty much everybody: students, teachers, professionals.
Designing the Research
Having written the problem statement, you have to design the research, which means formulating research questions, deciding the method of data gathering, and so on. Can you use Generative AI to design the research? Of course, and many people are doing exactly that. Should you use Generative AI to design the research? If research is part of your core skills or if you are going to use the output for key decisions or submissions, I would suggest using Generative AI for ideation and validation rather than for design. If research is not a skill, and you are going to use the output for information purposes or as part of your study or skill development, then you can use Generative AI for design and brainstorming — query the designs, ask for options, ask for reasons for each design option. That will help you understand and evaluate what the platform is producing and match it against your problem statement and goal.
In my research, I defined the design parameters, stated the methodology, defined what should not be done, and then asked Claude to provide me design options, and then selected one and refined it.
Here is a summary of parameters, specifications, and other design requirements I provided to Claude:
- Comparison over time and then a focus. Ideally, total courses available say in 2015, 2020, 2024 and then in 2025.
- Completion rates are absolutely critical since they are the proof of the pudding and will provide some indications.
- Pricing indications are good, but what would be more relevant is whether people are opting for free or priced courses.
- In research, the quality of data is most important. Data has to be from official sources — no blog reports or 'industry estimates' or 'expert opinion'.
- Further, what will you do if you don't get official data for required dates? What happens if you don't get data for the globe? Pick a region or country. I usually pick USA, India, and EU because official numbers are usually available in some form or the other.
- Further, regarding the courses themselves — it would help to have overall numbers for all AI-related courses at all levels (a big number typically) but then have details of AI fundamentals, AI for beginners, AI intro type software courses, and then segregate by education (college, universities), professional (IBM, Microsoft, etc.), EdTech (Coursera, Deep Learning AI, etc.) and finally independent courses (offered by small local or expert instructors).
- What is my objective? To provide clarity. So, with regards to Definition Consistency: simply add the definition and duration range for each category of course. That will help people understand that a $20 course that can be completed in 2 hours may be quicker, cheaper and good for understanding of a detailed part of a single topic — and that a $299 university certificate may help build deeper understanding and have greater credibility in the job market.
- Data lag — address by stating upfront 'data as of' and by ensuring we tabulate only if data is available for the years agreed. Contingency: we can go with 2015, 2020, 2025 or 2020, 2024, 2025 and by taking just one specific AI fundamentals course type.
- No backup plan (blogs, estimates, etc.) — I don't want to present data that readers can't verify. That is the point of picking government data. I would even avoid academic papers since they are not good for my purpose — they have limited data and usually solve research problems by reducing scope to tiny manageable areas.
- Let the data speak: if data is not available, this is an unorganised sector. Ignore seasonal fluctuations (semester-driven offerings) because AI courses in 2023 were vastly different from now, so seasonal differences are the least of our problems.
- Price parity between regions — not relevant since prices should be presented as-is with an internet exchange rate equivalent in USD as of July 18 2025.
As you may see, I provided as input a comprehensive framework for the gathering of data.
Data Gathering, Collation
If the research is mainly on the internet, I leave this task to the platform but cross-check each and every data set against the actual source to ensure that there are no errors, that the sources are what I had asked for (government or other authoritative source). The main role in these phases is to ensure that you check the source directly — the PDF or document or report where the data comes from, instead of an article or paper reference or summary. This delegates the automated, repetitive legwork to the platform and lets you focus on quality and accuracy.
Analysis and Findings
Interpretation of data is what differentiates one person's perspective from other perspectives. For this reason itself, it is important to analyse the data yourself, state possible interpretations, compare to alternative opinions (AI is very good at providing those alternative opinions) and finally write your findings — which means coming to a conclusion about what the research revealed in relation to your problem statement. If you do not write or at least dictate the approach to writing the findings and leave it to the AI platform, the research report will end up saying and reading more or less like other existing reports, since AI learns only from published data and as such mimics existing perspectives. It doesn't write or create perspectives.
Case Study Research Summary
So what were the findings from my research? Here is a summary.
(The full report is available at: claude.ai/public/artifacts/a5768cca-f76f-4de0-8912-fc03e93e91e0)
| Field | Detail |
|---|---|
| Research Objective | Find total number of 'Introduction to AI' courses globally with historical comparison (2015, 2020, 2024, 2025), completion rates, and free vs. paid enrolment patterns |
| Research Parameters | Official government sources, university reports, and SEC filings only |
| Geographic Scope | United States, India, European Union |
| Research Conducted | March 2026 |
| Methodology | Systematic search of official government databases, university reports, and regulatory filings |
| Limitation | Analysis restricted to official sources only; industry reports and surveys excluded per research parameters |
Summary
After conducting systematic research through official government databases, university systems, and regulatory filings, this investigation reveals a critical data gap: the AI education sector operates largely without standardised tracking or reporting requirements. Unlike traditional higher education, which has comprehensive government oversight, the online AI education boom is proceeding without systematic data collection on course offerings, enrolment patterns, or learning outcomes.
Key Findings
Official sources that provide historical course count data, completion rates, or comprehensive enrolment statistics necessary to substantiate claims about the explosive growth of AI education could not be found.
Data availability by research objective:
| Objective | Data Available |
|---|---|
| Historical Course Counts | 0% |
| Completion Rates | 0% |
| Free vs. Paid Patterns | 10% |
| Learning Outcomes | 0% |
| Provider Comparisons | 15% |
Regulatory coverage comparison:
| Metric | Traditional Higher Education | AI / Online Education |
|---|---|---|
| Government Tracking | 100% | 10% |
| Completion Reporting | 100% | 0% |
| Outcome Verification | 100% | 0% |
| Consumer Protection | 100% | 5% |
| Standardised Metrics | 100% | 0% |
Missing Critical Data
- Historical growth trends
- Success and completion rates
- Learning outcome verification
- Cross-platform comparisons
Conclusion
The absence of official data creates an environment where educational platforms can make claims about explosive growth and millions of learners without standardised verification or context about learning outcomes. Unlike traditional higher education, which operates under extensive government oversight and data collection requirements, the online AI education sector operates with minimal regulatory framework for outcome tracking.
The rapid growth claims for AI in education cannot be easily verified or disputed based on official sources, suggesting a need for standardised course classification systems, mandatory completion rate reporting, systematic tracking of educational outcomes, and consumer protection through verified claims.
Recommendations for Future Research
- Focus on specific institutional programs where enrolment and outcome data is systematically tracked, rather than seeking global course counts.
- Research the absence of oversight in online education versus traditional higher education regulation as a policy issue.
- Document specific examples of official institutional AI-in-education initiatives with detailed data, rather than attempting comprehensive global statistics.
- Treat the lack of data itself as the focus — examining why this educational sector operates without systematic tracking when such data would benefit learners, employers, and policymakers.
This research, conducted exclusively through official government sources, university systems, and regulatory filings, reveals that the AI education sector's growth claims cannot be verified through official data sources. The absence of systematic tracking represents a significant gap in educational oversight and consumer protection. While individual initiatives (such as the California State University system's 460,000-student AI rollout) demonstrate institutional commitment to AI education, the sector lacks the comprehensive data infrastructure necessary to support claims about global trends, effectiveness, or optimal approaches to AI learning.
This finding suggests that readers should approach AI education marketing claims with scepticism and focus on verifiable institutional credentials, clear learning objectives, and programs with transparent outcome reporting rather than enrolment numbers alone.
This case study shows that we can use Generative AI tools for practical purposes to help us make informed decisions in our everyday lives.